Imputr concepts#
There are a number of core concepts on which the Imputr is built and are good to know when using the library. Some concepts are specific to the Imputr library and some are general imputation concepts.
Univariate vs Multivariate#
Imputation techniques can be divided into two categories: univariate and multivariate.
Univariate techniques only base the imputation on the data that is in the target column (the column that undergoes imputation). An example of this is is the imputr.strategy.MeanStrategy.
Multivariate techniques use columns additional to the target column (feature columns) to impute the target column. An example of this is the imputr.strategy.RandomForestStrategy, where multiple columns are used as features to train a RandomForest model.
Cyclical imputation#
Cyclical imputation is the concept of having multiple iterations of full table imputations. The idea is that in a first full multivariate table imputation, at training time for some target column A, the missing values of feature columns [B’] (B for feature column, B’ for feature column that has not undergone imputation yet) are temporarily imputed with a stable strategy such as the MeanStrategy. After A full imputation run, a second imputation run can be initiated, for which the same strategy for a target column A with feature columns [B] is fitted and used to impute the cells that were originally missing.
Note
This feature has not been implemented yet. Please see our issues to contribute or follow its status.
Imputation order#
Imputation order The reason the order of imputation matters is because of the cyclical imputation dynamics.
- The default and recommended imputation order of the library is partially based on the missForest paper. In short:
columns with a univariate strategy are prioritised over columns with a multivariate strategy.
(for multivariate) columns with less missing values are prioritized over columns with more missing values.
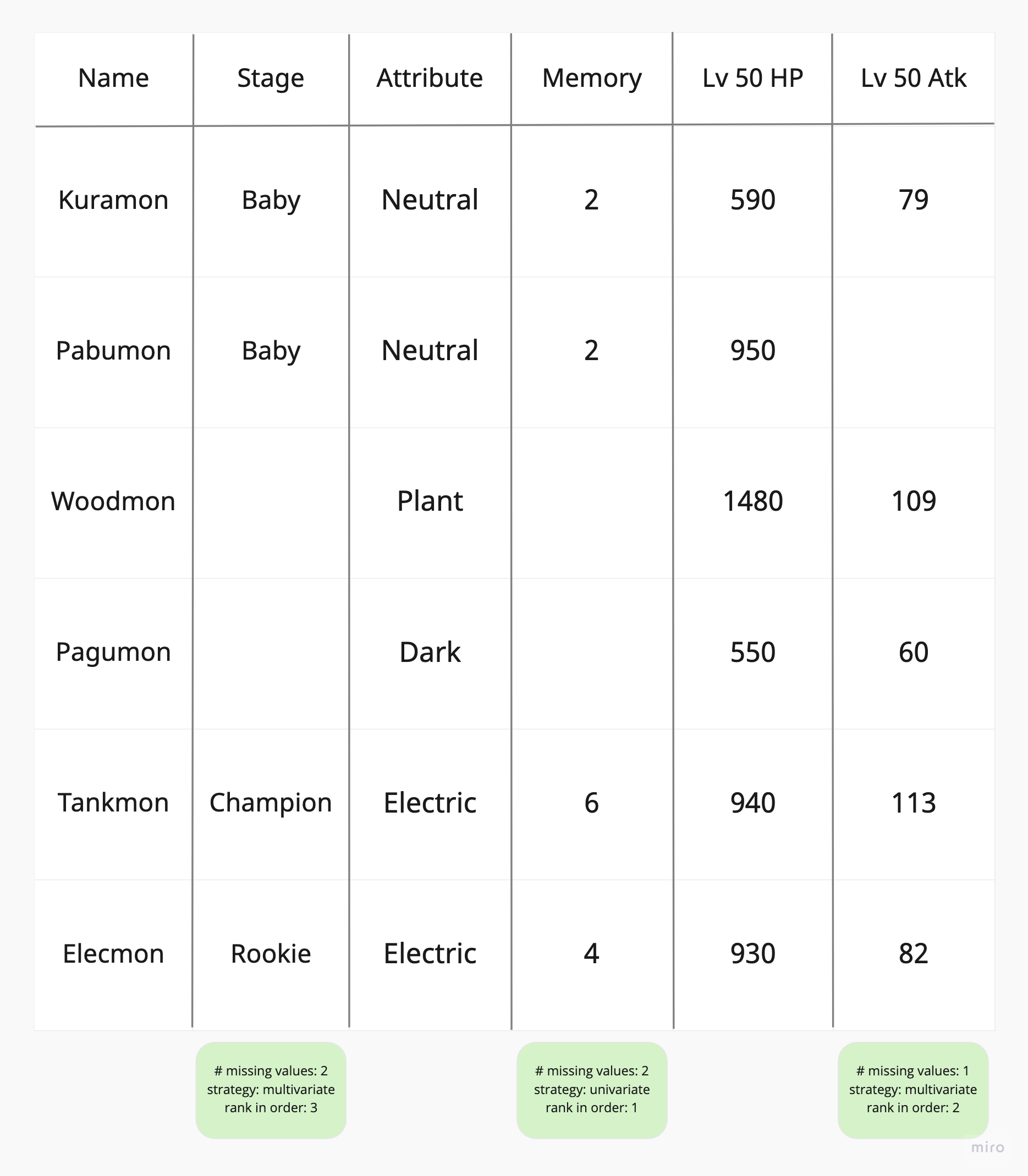
- Here is an example where:
the Memory column has 2 missing values but has a univariate strategy, putting it in first place.
the Lv 50 Atk column has 1 missing value with a multivariate sttategy, putting it in second place
and the Stage column comes in last place as it has both a multivariate strategy and most missing values.
Missing at completely random#
Missing at completely random (MCAR) happens when reanons for any particular data-item that is missing is independent both of observable variables and of unobservable parameters.It must happen entirely at random. When data are MCAR, the analysis performed on the data is unbiased.
Note
MCAR generally is a good sign for analysis and imputation. However, real-world data is rarely MCAR.
Missing at random#
Missing at random (MAR) is when the missingness actually is not random and can be fully considered by looking at the variables that contain complete information. MAR is an assumption that is impossible to verify statistically, which means it relies on the assumptions of the data scientist. An example is that males are less likely to fill in a depression survey but this has nothing to do with their level of depression, after accounting for maleness. Depending on the analysis method, these data can still induce parameter bias in analyses due to the contingent emptiness of cells (male, very high depression may have zero entries for example).
Missing not at random#
Values in a data set are missing not at random (MNAR) when data that contains missing values is neither MAR or MCAR (i.e. the value of the variable that’s missing is related to the reason it’s missing). An example for this could be a survey where people that earn a salary that is significantly lower or higher than the national average, which would make them less inclined to fill in this value.